Title: 저평가된 부동산예측
member : 도시공학과, 손XX ,2019074639, sonsj97@naver.com
Ⅰ. Proposal (Option A)
Motivation
일반 국민들이 직장을 잡고 안정적인 수입이 들어오는 것은 어느 정도 한계가 있습니다. 즉, 소득의 유한성이 있는 것이고, 이로 인해 노후대비가 필수적이라고 할 수 있습니다. 대한민구 국민 모두가 노후 대비를 한다고 할 때 가장 안전하고 실속 있는 길은 부동산 투자라고 생각합니다. 부동산 투자는 미래를 예측할 수 있는 능력을 필요로 합니다.
What do you want to see at the end?
부동산 투자를 통해 높은 수익을 얻으려면 저평가된 부동산을 볼 수 있는 시각이 중요합니다. 이번 프로젝트를 통해 부동산 값에 미치는 영향요소를 파악하고 앞으로 성장할 가능성이 높은 부동산을 예측하는 것을 목표로 합니다.
(분석대상은 아파트에 한정합니다.)
Ⅱ. Datasets
A. 데이터 출처
https://www.data.go.kr/data/15058453/openapi.do
국토교통부_공동주택 기본 정보제공 서비스
(공동주택 기본정보)공동주택관리정보시스템에 가입한 단지의 기본정보 및 상세정보 제공
www.data.go.kr
https://www.data.go.kr/data/15057511/openapi.do
국토교통부_아파트매매 실거래 상세 자료
부동산 거래신고에 관한 법률에 따라 신고된 주택의 실거래 자료를 제공
www.data.go.kr
B. 데이터명(내적, 외적)
| <내적요소> | <외적요소> |
| 아파트 매매가 | |
| 단지분류 | 백화점(반경1km) |
| 세대수 | 학교(반경500m) |
| 난방방식 | 은행(반경500m) |
| 시공사 | 카페(반경500m) |
| 시행사 | 병원(반경500m) |
| 주택관리업자 | 편의점(반경50m) |
| 일반관리-인원 | 버스정류장(50m) |
| 경비관리-인원 | 지하철(500m) |
| 청소관리-인원 | 어린이집, 유치원(500m) |
| 음식물 처리방법 | 학원(500m) |
| 급수방식 | 주유소, 충전소(1km) |
| 승강기(승객용) | 문화시설(1km) |
| 지상주차대수 | 공공기관(500m) |
| 지하주차대수 | 관광명소(2km) |
| CCTV대수 | 음식점(500m) |
| 주차관제, 홈네트워크 | 중개업소(500m) |
| 도로명주소 | |
| 부대복리시설 | |
| 동리 | |
| 단지명 | |
<DataSet>
Ⅲ. Methodology
LightGBM, 랜덤 포레스트, XGBoost, optuna 하이퍼파라미터 최적화를 통해서 분석을 진행해보려고 한다.
- LightGBM

Light GBM은 Gradient Boosting 프레워크로 Tree 기반 학습 알고리즘입니다.
기존의 다른 Tree 기반 알고리즘과 어떻게 다를까요?
Light GBM은 Tree가 수직적으로 확장되는 반면에 다른 알고리즘은 Tree가 수평적으로 확장됩니다, 즉 Light GBM은 leaf-wise 인 반면 다른 알고리즘은 level-wise 입니다. 확장하기 위해서 max delta loss를 가진 leaf를 선택하게 되는 것이죠. 동일한 leaf를 확장할 때, leaf-wise 알고리즘은 level-wise 알고리즘보다 더 많은 loss, 손실을 줄일 수 있습니다.
- XGBoost Regression
1. 정의
- 약한 분류기를 세트로 묶어서 정확도를 예측하는 기법이다.
- 욕심쟁이(Greedy Algorithm)을 사용하여 분류기를 발견하고 분산처리를 사용하여 빠른 속도로 적합한 비중 파라미터를 찾는 알고리즘이다.
- boostin 알고리즘이 기본원리
2. 장점
- 병렬 처리를 사용하기에 학습과 분류가 빠르다
- 유연성이 좋다. 커스텀 최적화 옵션을 제공한다
- 욕심쟁이(Greedy-algorithm)을 사용한 자동 가지치기가 가능하다. 과적합이 잘일어나지 않는다.
- 다른 알고리즘과 연계하여 앙상블 학습이 가능하다.
3. 파라미터
1) 일반 파라미터 - 도구의 모양을 결정
- booster : 어떤 부스터 구조를 쓸지 결정한다. ( gbtree, gblinear, dart)
- nthread : 몇개의 쓰레드를 동시에 처리하도록 할지 결정한다. 디폴트는 '가능한 많이'
- num_feature : feature차원의 숫자를 정해야하는 경우 옵션을 세팅. '디폴트는 가능한 많이'
2) 부스트 파라미터 - 트리마다 가지를 칠 때 적용하는 옵션을 정의
- eta: learning rate와 같다. 트리에 가지가 많을 수록 과적합하기 쉽다. 매 부스팅 스탭마다 weight를 주어 부스팅 과정에 과적합이 일어나지 않도록 한다.
- gamma: 정보흭득(information Gain)에서 -r로 표현한 바 있다. 이것이 커지면, 트리 깊이가 줄어들어 보수적인 모델이 된다. ( 디폴트는 0 )
- max_depth : 한 트리의 maxium depth. 숫자가를 키울수록 보델의 복잡도가 커진다. 과적합 하기 쉽다. 디폴트는 6, 이 때 리프노트의 개수는 최대 2^6 = 64개이다.
- lambda (L2 reg-form) : L2 Regularization Form에 달리는 weights이다. 숫자가 클수록 보수적인 모델이 된다.
- alpha(L1 reg-form) : L1 Regularization Form에 달리는 weights이다. 숫자가 클수록 보수적인 모델이 된다.
3) 학습과정 파라미터 - 최적화 퍼모먼스를 결정
- objective : 목적함수이다. reg:linear(linear-regression), binary:logistic(binary-logistic-classification), count:poisson(count data poison regression) 등 다양
- eval_metric : 모델의 평가 함수를 조정하는 함수 - rmse(root mean square error), logloss(log-likelihood), map(mean average precision) 등 데이터의 특성에 맞게 평가 함수를 조정
4) 커멘드 라인 파라미터
- num_rounds : 부스팅 라운드를 결정한다. 랜덤하게 생성되는 모델이니만큼 이 수 가 적당히 큰게 좋다 epochs 옵션과 동일하다.
- 랜덤 포레스트
- 이제 Random Forest 에 대해서 다뤄보겠습니다.
- Forest(숲)은 무엇으로 이루어져 있을까요? 나무입니다.
- 수많은 나무가 한군데 어우러져 비로소 울창한 숲을 만드는 것이죠.
- 마찬가지로 Random Forest는, 수많은 의사 결정 트리(Decision Tree)가 모여서 생성됩니다.
- 상단 의사 결정 트리 예제에서는, 건강 위험도를 세 가지 요소와 한가지 의사 결정 트리로 인해서 결정했습니다.
- 하지만, 건강 위험도를 예측하려면 세 가지 요소보다 더 많은 요소를 고려하는 것이 바람직할 것입니다.
- 예를 들어, 성별, 키, 몸무게, 거주지역, 운동량, 기초 대사량, 근육량 등 수많은 요소도 건강에 큰 영향을 미칩니다.
- 하지만, 이렇게 수많은 요소(Feature)들을 기반으로 건강 위험도(Target)를 예측한다면, 분명 오버피팅이 일어날 것입니다.
- 예를 들어, Feature가 30개라고 합시다.
- 30개의 Feature를 기반으로 하나의 결정 트리를 만든다면 트리의 가지가 많아질 것이고, 이는 오버피팅이 될 것입니다.
- 따라서, Random Forest 는 전체 Feature 중 랜덤으로 일부 Feature만 선택해 하나의 결정 트리를 만들고, 또 전체 Feature 중 랜덤으로 일부 Feature를 선택해 또 다른 결정 트리를 만들며, 여러 개의 의사 결정 트리를 만드는 방식으로 구성됩니다.
- 의사 결정 트리마다 하나의 예측 값을 내놓습니다.
- 이렇게 여러 결정 트리들이 내린 예측 값들 중, 가장 많이 나온 값을 최종 예측값으로 정합니다.
- 다수결의 원칙에 따르는 것입니다.
- 이렇게 여러 가지 결과를 합치는 방식을 앙상블(Ensemble)이라고 합니다.
- 즉, 하나의 거대한 (깊이가 깊은) 결정 트리를 만드는 것이 아니라 여러 개의 작은 결정 트리를 만드는 것입니다.
- 여러 개의 작은 결정 트리가 예측한 값들 중, 가장 많이 등장한 값(분류일 경우) 혹은 평균값(회귀일 경우)을 최종 예측 값으로 정하는 것입니다.
- 문제를 풀 때도 한 명의 똑똑한 사람보다 100 명의 평범한 사람이 더 잘 푸는 원리입니다.
- 그럼 다시, Random Forest의 Random은 무엇이 무작위적이라는 것일까요?
- Random은, 각각의 의사 결정 트리를 만드는데 있어 쓰이는 특징들을(흡연 여부, 나이, 등등) 무작위로 선정한다는 의미입니다.
- 예를 들어, 건강 위험도를 30개의 특징들로 설명할 수 있다면,
- 30개의 특징들 중 무작위로 일부만 선택하여,
- 가장 건강 위험도를 잘 예측할 수 있는 하나의 트리를 구성한다는 의미입니다.
- 다음은 Random Forest가 완성되는 과정입니다.
- 전체 특징 중 일부 특징을 무작위로 선택합니다.
- 흡연 여부, 키, 몸무게, 나이가 선택되었다고 가정
- 선택된 일부 특징을 사용해, 가장 건강 위험도를 잘 예측할 수 있는 하나의 트리를 구성
- 원하는 개수의 트리가 생성되기까지 위 과정을 반복합니다.
- 트리의 개수는 데이터 사이언티스트가 원하는 만큼 생성이 가능
- 그렇다면, 왜 Random Forest는 의사 결정 트리의 한 단계를 만들 때마다 모든 요소를 고려하지 않을까요?
- 그것은 역설적으로 모든 요소를 고려하기 위함입니다.
- 만약 의사 결정 트리의 한 단계를 만드는데 모든 요소를 고려한다면,
- 모든 의사 결정 트리가 같은 5~6개의 요소만을 가지고 생성
- 고려해야 할 요소는 30개인데, 모든 트리가 흡연 여부, 나이, 식단, 몸무게, 성별 등으로 구성되게 됩니다.
- 하지만, 아무리 5~6개의 요소가 가장 “똑똑한” 요소들 이어도, 나머지 25개의 “덜 똑똑한” 요소들을 고려하는 것이 최종 목적
- 전교 1등 한 명보다 전교 5등 100명이 아는 것이 더 많은 것과 비슷한 원리
- 이처럼 여러 개의 결정 트리를 통해 랜덤 포레스트를 만들면 오버피팅 되는 단점을 해결
랜덤 포레스트의 장점
- Classification(분류) 및 Regression(회귀) 문제에 모두 사용 가능
- Missing value(결측치)를 다루기 쉬움
- 대용량 데이터 처리에 효과적
- 모델의 노이즈를 심화시키는 Overfitting(오버피팅) 문제를 회피하여, 모델 정확도를 향상시킴
- Classification 모델에서 상대적으로 중요한 변수를 선정 및 Ranking 가능
optuna 하이퍼파라미터 최적화

Ⅳ. Analysis & Evaluation
1. 아파트의 내적요소와 아파트 값의 관계
1) 결측치 처리
for cat in categories:
le = LabelEncoder()
df[cat].fillna("missing", inplace=True)
le=le.fit(df[cat])
df[cat] = le.transform(df[cat])
df[cat] = df[cat].astype("category")결측치를 missing으로 변환한 후 LabelEncoder를 사용하여 문자 데이터를 수치 데이터로 바꿈
plt.figure(figsize=(10,10))
sns.heatmap(inner_corr, vmax=1, vmin=-1, center=0, annot=True)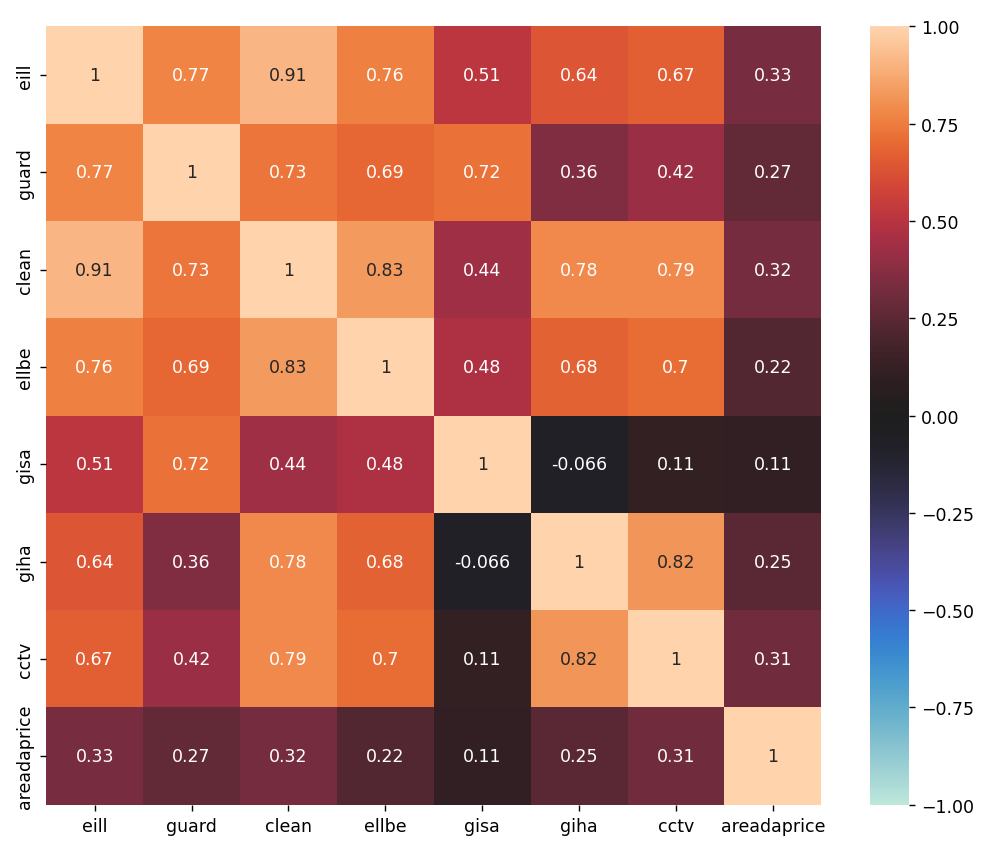
2) LightGBM 교차 검증으로 모델 학습과 예측
데이터셋을 Train, Test 데이터셋으로 분리하기
from sklearn.model_selection import train_test_split
train_X, x_test, train_Y, y_test = train_test_split(x, y, test_size=0.3, shuffle=True,random_state=42)train_df_le = train_X
train_df_le['areadaprice'] = train_Y
train_df_le = train_df_le.reset_index(drop=True)
folds = 3
kf = KFold(n_splits = folds)
lgbm_params = {
"objective":"regression",
"random_seed":1234
}
train_X = train_df_le.drop(['areadaprice'], axis=1)
train_Y = train_df_le['areadaprice']
models = []
rmses = []
oof = np.zeros(len(train_X))
for train_index, val_index in kf.split(train_X):
X_train = train_X.iloc[train_index]
X_valid = train_X.iloc[val_index]
y_train = train_Y.iloc[train_index]
y_valid = train_Y.iloc[val_index]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train)
model_lgb = lgb.train(lgbm_params,
lgb_train,
valid_sets = lgb_eval,
num_boost_round=100,
early_stopping_rounds=20,
verbose_eval = 10,
)
y_pred = model_lgb.predict(X_valid, num_iteration=model_lgb.best_iteration)
tmp_rmse = np.sqrt(mean_squared_error(np.log(y_valid), np.log(y_pred)))
print(tmp_rmse)
models.append(model_lgb)
rmses.append(tmp_rmse)
oof[val_index] = y_pred
위 코드를 실행하면 다음과 같은 계산과정이 보여지고 결과가 나온다.
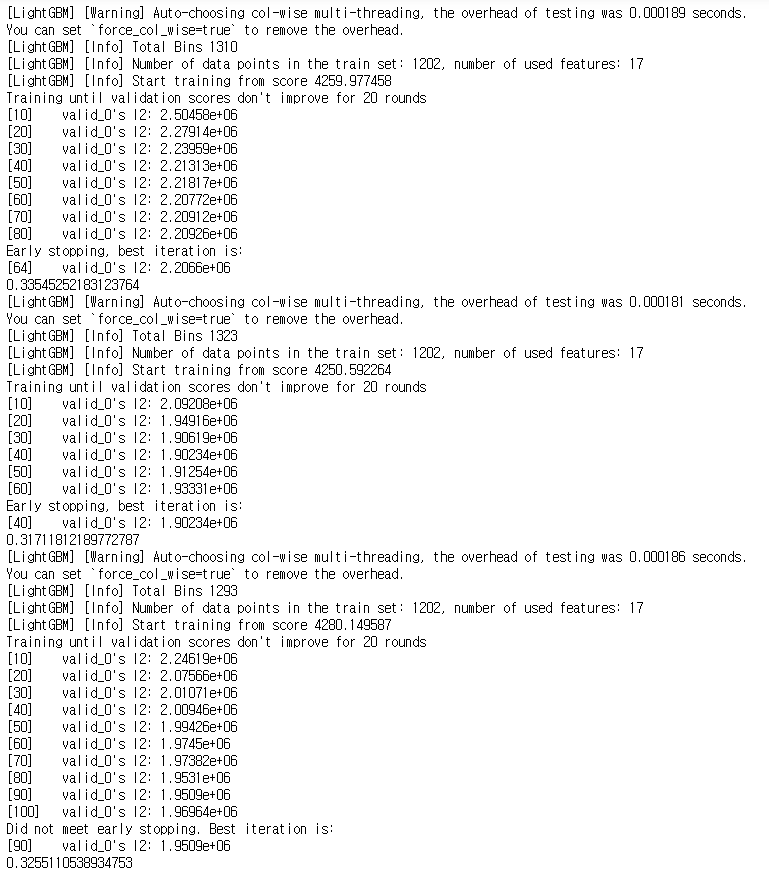
출력 결과의 평균 RMSE(평균 제곱근 편차)를 계산해보겠다.
sum(rmses)/len(rmses)
0.3260272325408136평균 RMSE 0.3260272325408136 이 나왔습니다. 이제부터 예측 정확도를 개선해보도록 하겠습니다.
3) 현재 예측 값과 실제 값 차이를 확인
actual_pred_df = pd.DataFrame({
"actual": train_Y,
"pred": oof
})
actual_pred_df.plot(figsize=(12,5))
plt.show()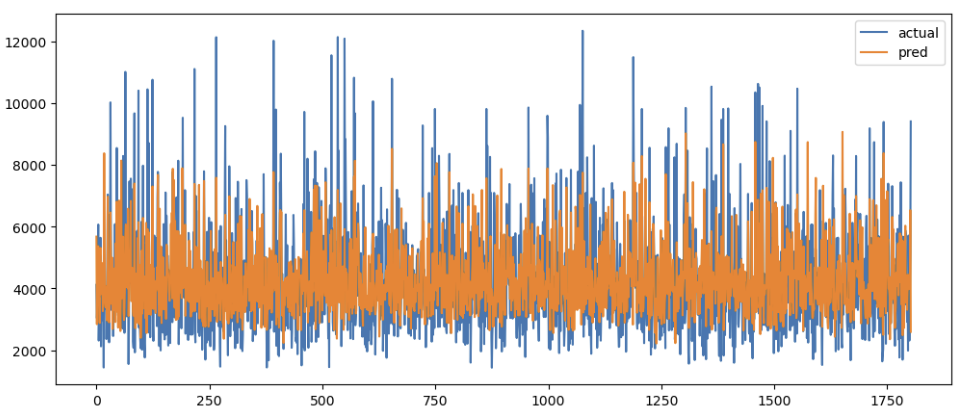
출력 그래프를 보면 예측 값이 실제 값 경향을 비슷하게 따라가는 것처럼 보이지만 실제 값이 많이 올라갈 때와 많이 내려갈 때에는 충분히 따라가지 못하고 있음을 알 수 있었습니다. 어떠한 이유인지 검토해보겠습니다.
테스트 데이터 셋으로 정확도 분석을 해보았습니다.
from sklearn.metrics import roc_auc_score,accuracy_score
preds=[]
rmses=[]
for model in models:
pred = model.predict(test_X)
preds.append(pred)
tmp_rmse = np.sqrt(mean_squared_error(y_valid,y_pred))
rmses.append(tmp_rmse)
preds_array = np.array(preds)
preds_mean = np.mean(preds_array, axis=0)
actual_pred_df = pd.DataFrame({
"actual": test_Y,
"pred": preds_mean
})
import matplotlib as plt
actual_pred_df.plot(figsize=(12,5))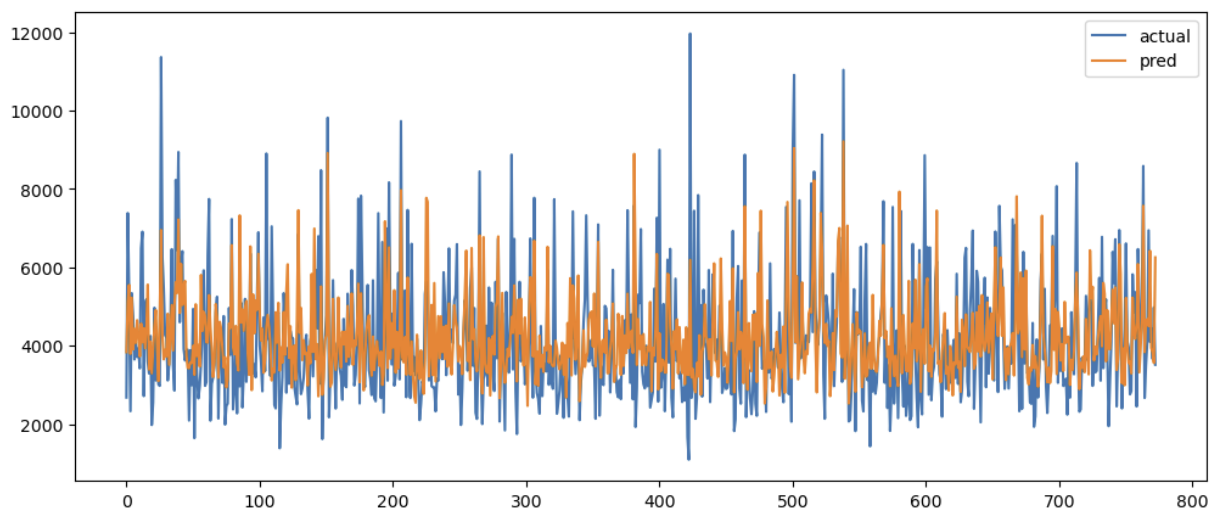
sum(rmses)/len(rmses)
0.3157180297087304테스트 데이터셋에서 0.3157180297087304의 평균 RMSE결과로 학습 데이터 결과인 0.3260272325408136 보다 더 높은 정확도를 보여줬습니다.
4) 각 변수의 중요도 확인
for model in models:
lgb.plot_importance(model, importance_type='gain', max_num_features=3)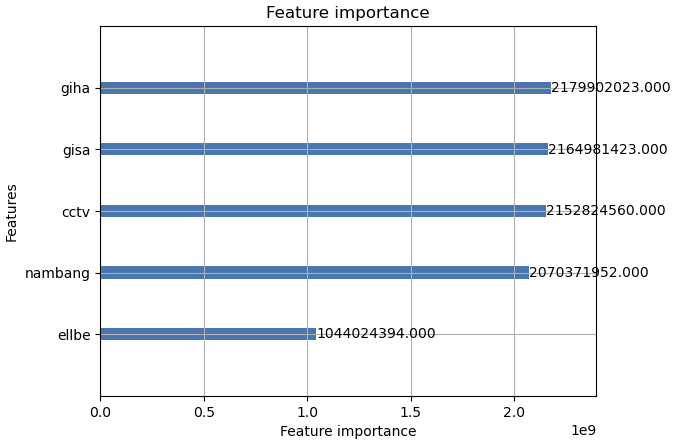
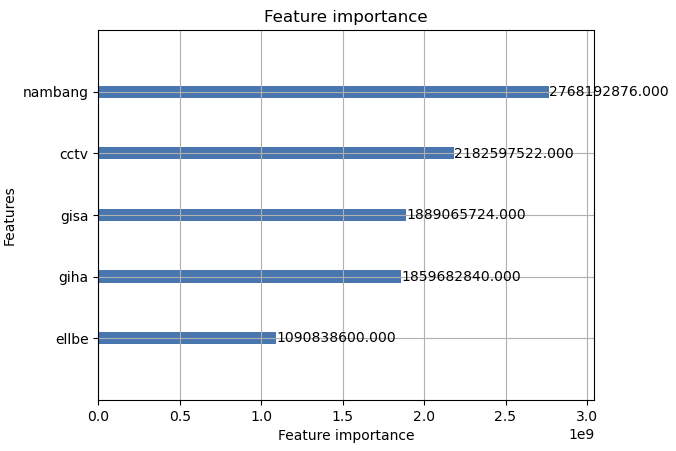
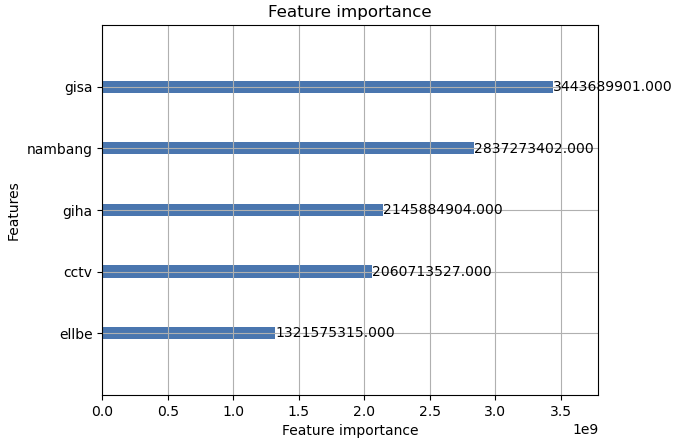
난방방식과 CCTV개수, 지상주차대수, 지하주차대수, 엘리베이터 개수가 상위 랭킹에 포함되어 있음을 알 수 있었습니다.
중요도 높은 데이터를 우선적으로 검토해보겠습니다.
5) 목적 변수의 전처리: 목적 변수의 분포 확인
train_df_le['areadaprice'].plot.hist(bins=20)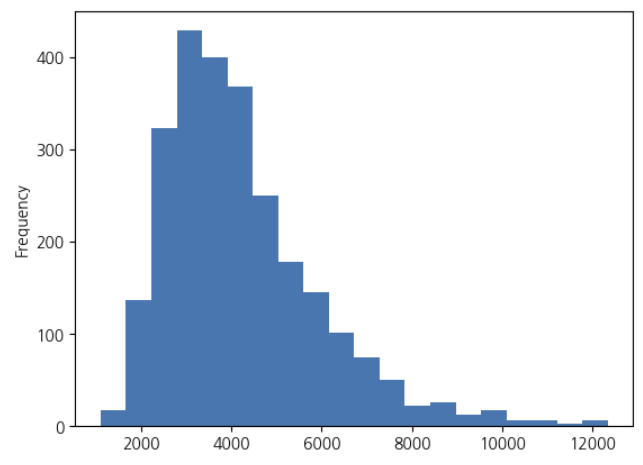
정규 분포처럼 중앙값이 가장 빈도가 좌우 대칭인 것이 아니라 왼쪽으로 치우쳐 있는 푸아송 분포를 보인다.
목적 변수를 로그화하겠습니다.
일반적으로 머신 러닝이나 통계적인 처리의 대부분은 데이터가 정규 분포임을 상정하고 있습니다.
또 평당 3000만원대 부근에 데이터가 많이 존재하고 있으므로 그 차이를 6000~7000만원대사이의 차이보다 상세하게 파악할 수 있도록 조사해야 할 것같다.
np.log(train_df_le['areadaprice']).plot.hist(bins=20)로그화된 평당가격 분포를 히스토그램으로 시각화
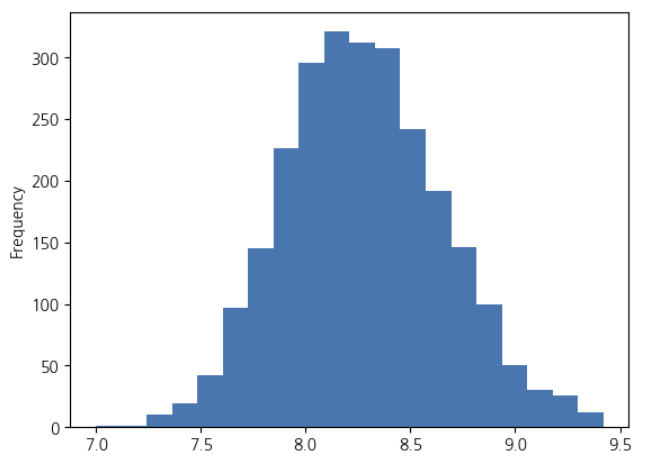
가장 많은 값을 중심으로 좌우 대칭에 가까운 분포를 보입니다.
7) 목적 변수를 로그화하여 예측 정확도 향상시키기
train_df_le['areadaprice_log'] = np.log(train_df_le['areadaprice'])
train_X = train_df_le.drop(["areadaprice", "areadaprice_log"], axis=1)
train_Y = train_df_le["areadaprice_log"]
import warnings
warnings.filterwarnings("ignore")
models = []
rmses = []
oof = np.zeros(len(train_X))
for train_index, val_index in kf.split(train_X):
X_train = train_X.iloc[train_index]
X_valid = train_X.iloc[val_index]
y_train = train_Y.iloc[train_index]
y_valid = train_Y.iloc[val_index]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train)
model_lgb = lgb.train(lgbm_params,
lgb_train,
valid_sets = lgb_eval,
num_boost_round=100,
early_stopping_rounds=20,
verbose_eval = 10,
)
y_pred = model_lgb.predict(X_valid, num_iteration=model_lgb.best_iteration)
tmp_rmse = np.sqrt(mean_squared_error(y_valid, y_pred))
print(tmp_rmse)
models.append(model_lgb)
rmses.append(tmp_rmse)
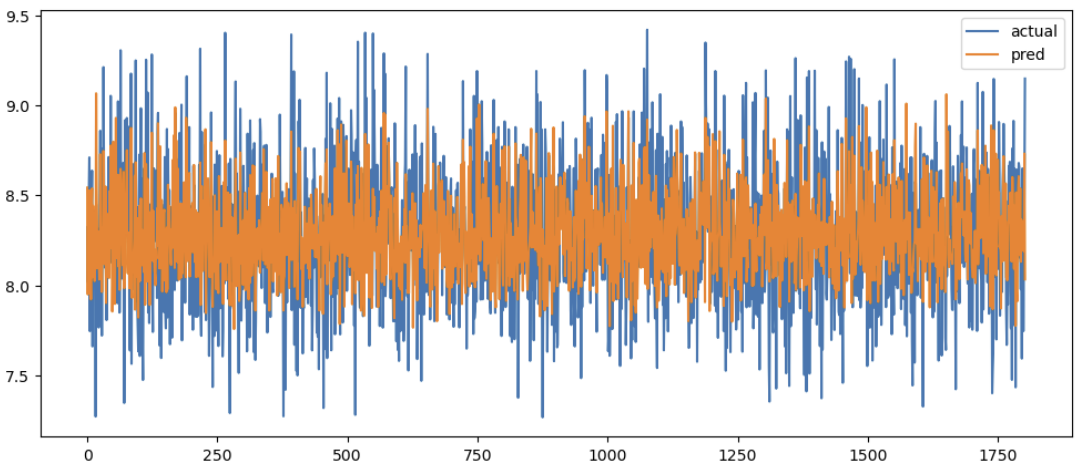
oof[val_index] = y_pred평균 RMSE 결과는 0.31946493274556814 으로 이전의 결과보다 조금 좋아졌다는 것을 확인할 수 있다.
sum(rmses)/len(rmses)
0.31946493274556814하지만 아직까지 실제값과 예측값의 차이가 크다는 것을 그래프를 통해서 볼 수 있다.
중요도 검사를 실시했을때는 이전과 별차이없이 지상주차대수, 지하주차대수, CCTV개수, 난방방식이 상위 랭킹을 차지하고 있음 확인하였다.
8) 설명 변수의 전처리: 결측치 확인
각 설명 변수에 결측치가 얼마나 포함되어 있는지 확인해 보겠다. 이 데이터셋에서 결측치는 다른것과 비교했을 때 중요하다고 판단된다. 결측치는 존재하지않다는 의미로도 해석될 수 있기 때문이다.
하지만 전체 결측치를 파악했을 때 크게 부족한 카테고리는 없는 것으로 생각된다.
inner.isnull().sum().sort_values(ascending=False).head(40)
9) 이상치 제외
이상치란 통산적인 경향과 다른 값을 이상치 혹은 극단 값이라고 합니다. 아상치가 데이터 내에 존재하면 과적합 가능성이 있어 예측 정확도가 떨어진다. 그래서 이상치는 학습할 때 제외하는 것이 좋다.
한편 이상치를 과도하게 판정하고 필요한 데이터까지 삭제하면 평균적인 데이터밖에 예측할 수 없다.
각 변수의 통계량을 확인해보면
inner.describe().T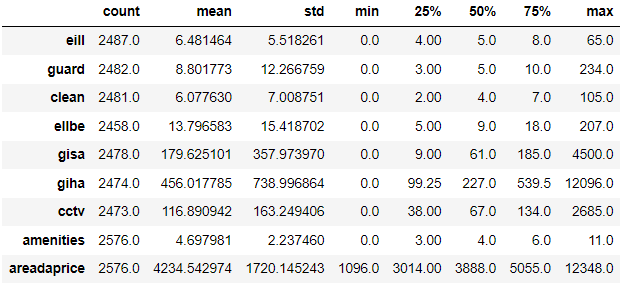
평균에서 표준편차에 대하여 최솟값, 최댓값이 크게 벗어나 있는 것이 있다.
수치데이터만 추출해서 이상치를 확인해보겠다.
inner_num = inner.select_dtypes(include=[np.number])
num_features = sorted(list(set(inner_num)))
for col in num_features:
tmp_df = inner_num[(inner_num[col] > inner_num[col].mean() + inner_num[col].std() *3) | (inner_num[col] < inner_num[col].mean() - inner_num[col].std()*3)]
print(col, len(tmp_df))
CCTV개수, 청소인원수, 일반관리인원, 승강기수, 지하주차장대수, 지상주차장대수,경비원수에 이상치가 발견되었다.
이상치를 포함하는 변수 분포를 시각화해보도록 하겠다.
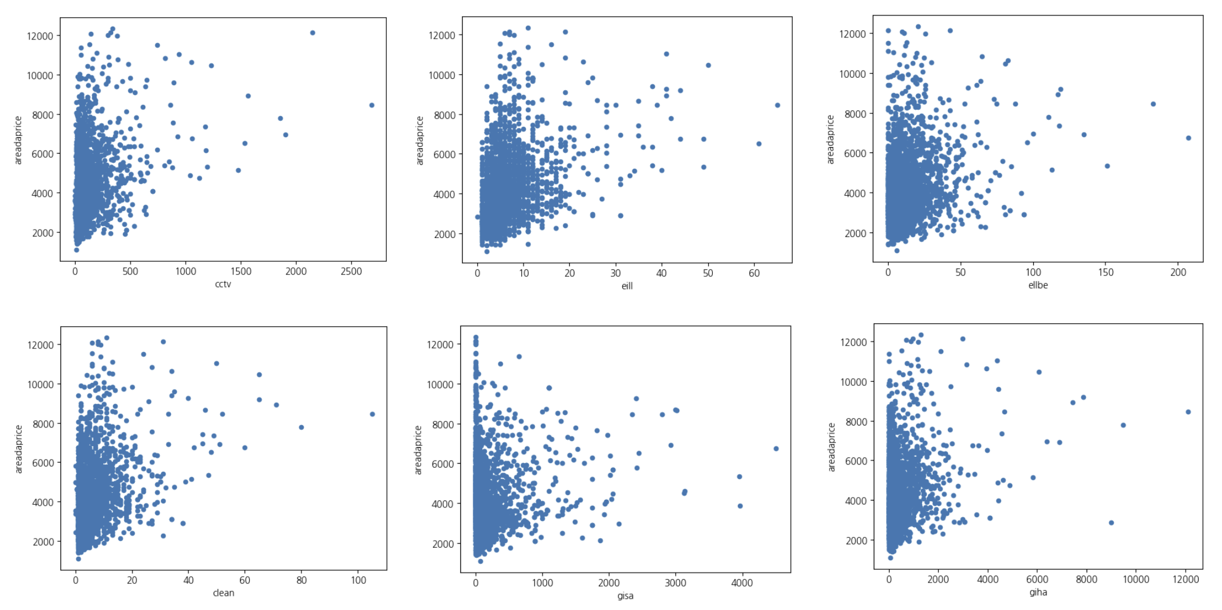
이상치를 제외할 때 주의할 점은 테스트 데이터는 이상치라고 해도 제외해서는 안된다는 것이다. 자칫 제외하면 해당 값을 예측할 수 없기 때문이다.
train_df_le = train_df_le[(train_df_le['cctv'] < 1300) | (train_df_le['areadaprice'].isnull())]
train_df_le = train_df_le[(train_df_le['clean'] < 55) | (train_df_le['areadaprice'].isnull())]
train_df_le = train_df_le[(train_df_le['eill'] < 45) | (train_df_le['areadaprice'].isnull())]
train_df_le = train_df_le[(train_df_le['ellbe'] < 120) | (train_df_le['areadaprice'].isnull())]
train_df_le = train_df_le[(train_df_le['giha'] < 7000) | (train_df_le['areadaprice'].isnull())]
train_df_le = train_df_le[(train_df_le['gisa'] < 2600) | (train_df_le['areadaprice'].isnull())]
train_df_le = train_df_le[(train_df_le['guard'] < 150) | (train_df_le['areadaprice'].isnull())]이상치가 제외된 데이터셋을 위에서 사용했던 로그값 LightGBM 분석을 진행한다.
sum(rmses)/len(rmses)
0.3157180297087304이상치를 제외한 데이터셋의 평균 RMSE값이 0.3157180297087304으로 결과가 더 좋아진 것을 확인할 수 있다.
10) 하이퍼파라미터 최적화
처음에 정해줬던 하이퍼파라미터는 다음과 같다.
lgbm_params = {
"objective":"regression",
"random_seed":1234
}기본적인 세팅만 했다. 하지만 하이퍼파라미터를 최적화해서 적용한다면 더 좋은 결과를 만들어 볼 수 있을 것이다.
하이퍼파라미터를 조정하는 방법 중 하나인 Optuna를 이용하여 하이퍼파라미터를 최적화해보도록 하겠다.
하이퍼파라미터는 하나만 변경해서는 정확도가 향상되지 않는 경우가 많아 복수의 하이퍼파라미터를 동시에 변경해야 할 때가 있다. 하지만 여러 하이퍼파라미터 값의 조합을 수동으로 일일이 테스트하거나 for문을 사용하여 무차별적으로 대입할 수는 없다.
이때 쓸 수 있는 파이썬의 하이퍼파라미터 최적화 라이브러리는 다양하다. 오랫동안 인기를 끌었던 그리드 검색을 사용하는 라이브러리와 베이지안 최적화를 이용해서 그리드 검색보다 계산량을 대폭 향상시킨 라이브러리 등이 있다.
베이지안 최적화를 이용한 방법 중에서도 최근 PFN에서 개발한 Optuna(http://optuna.org/)라이브러리가 하이퍼파라미터를 효율적으로 선택하므로 이것을 사용해 보겠다.
import optuna
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(train_X, train_Y, test_size=0.2, shuffle=False, random_state=1234)
def objective(trial):
params = {
"objective": "regression",
"random_seed": 1234,
"learning_rate": 0.05,
"n_estimators":1000,
"num_leaves":trial.suggest_int("num_leaves",4,64),
"max_bin":trial.suggest_int("max_bin", 50,200),
"bagging_freq":trial.suggest_int("bagging_freq", 1,10),
"feature_fraction":trial.suggest_uniform("feature_fraction", 0.4, 0.9),
"min_data_in_leaf":trial.suggest_int("min_data_in_leaf", 2,16),
"min_sum_hessian_in_leaf":trial.suggest_int("min_sum_hessian_in_leaf", 1,10),
}
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train)
model_lgb = lgb.train(lgbm_params,
lgb_train,
valid_sets = lgb_eval,
num_boost_round=100,
early_stopping_rounds=20,
verbose_eval = 10,
)
y_pred = model_lgb.predict(X_valid, num_iteration=model_lgb.best_iteration)
score = np.sqrt(mean_squared_error(y_valid, y_pred))
return score<결과>
{'num_leaves': 48,
'max_bin': 97,
'bagging_freq': 6,
'feature_fraction': 0.8221328742905087,
'min_data_in_leaf': 13,
'min_sum_hessian_in_leaf': 4}
출력 결과는 50회 시행 중 가장 정확한 하이퍼파라미터를 보여줍니다. 하이퍼파라미터와 범위를 여러 번 조정하여 실행하면서 시행착오를 겪는 것도 좋다고 생각한다.
여기서 나온 하이퍼파리미터를 그대로 적용하여 위해서 마지막에 했던 교차 검증을 다시 해보겠다.
sum(rmses)/len(rmses)
0.311912066928113위에서 마지막으로 했던 평균 RSME는 0.3157180297087304 이었지만 하이퍼파라미터를 조정하니
0.311912066928113 로 지금까지 가장 향상폭이 높아졌다는 것을 확인할 수 있다.
(하이퍼파라미터의 중요성)
테스트 데이터셋에서 확인해보았다.
preds=[]
test_rmses=[]
for model in models:
pred = model.predict(x_test)
preds.append(pred)
tmp_rmse = np.sqrt(mean_squared_error(y_test, pred))
test_rmses.append(tmp_rmse)
actual_pred_df = pd.DataFrame({
"actual": y_test,
"pred": preds_mean
})
import matplotlib as plt
actual_pred_df.plot(figsize=(12,5))
sum(test_rmses)/len(test_rmses)
0.2087949508799556평균 RMSE결과는 0.2087949508799556 로 좋은 결과가 나왔다.
11) 랜덤 포레스트 교차 검증으로 모델 학습과 예측
folds = 3
kf = KFold(n_splits = folds)
models_rf = []
rmses_rf = []
oof_rf = np.zeros(len(train_X))
for train_index, val_index in kf.split(train_X):
X_train = train_X.iloc[train_index]
X_valid = train_X.iloc[val_index]
y_train = train_Y.iloc[train_index]
y_valid = train_Y.iloc[val_index]
model_rf = rf(n_estimators=50, random_state=1234)
model_rf.fit(X_train, y_train)
y_pred = model_rf.predict(X_valid)
tmp_rmse = np.sqrt(mean_squared_error(y_valid, y_pred))
print(tmp_rmse)
models_rf.append(model_rf)
rmses_rf.append(tmp_rmse)
oof_rf[val_index] = y_pred0.8508608396869068
0.7314913130577209
0.7846327980052538결과는 LightGBM 보다 훨씬 좋지않은 결과가 도출되었음을 알 수 있습니다.
12) XGBoost 교차 검증으로 모델 학습과 예측
이어서 LightGBM처럼 그레이디언트 부스팅 결정 트리를 실행하는 XGBoost를 실행해 보겠다.
XGBoost는 매우 정확해서 예측할 때 유용하지만, 실행속도는 LightGBM이 더 우수해서 최근 몇 년간은 대용량 데이터를 예측할 때 LightGBM을 널리 사용해 왔다. 하지만 LightGMB으로 학습해서 특징 값을 만들거나 전처리 후 XGBoost로 최종 예측 결과를 결합하는 방법도 자주 사용한다.
Optuna로 하이퍼파라미터 조정 후 실행하였다.
import xgboost as xgb
import warnings
warnings.filterwarnings("ignore")
xgb_params = {
"learning_rate": 0.05,
"seed":1234,
"max_depth":16,
'colsample_bytree': 0.6723266255813145,
'sublsample': 0.42204121944850725
}
models_xgb = []
rmses_xgb = []
oof_xgb = np.zeros(len(train_X))
for train_index, val_index in kf.split(train_X):
X_train = train_X.iloc[train_index]
X_valid = train_X.iloc[val_index]
y_train = train_Y.iloc[train_index]
y_valid = train_Y.iloc[val_index]
xgb_train = xgb.DMatrix(X_train, label=y_train)
xgb_eval = xgb.DMatrix(X_valid, label=y_valid)
evals = [(xgb_train, "train"), (xgb_eval, "eval")]
model_xgb = xgb.train(xgb_params,
xgb_train,
evals= evals,
num_boost_round=1000,
early_stopping_rounds=20,
verbose_eval = 20,
)
y_pred = model_xgb.predict(xgb_eval)
tmp_rmse = np.sqrt(mean_squared_error(y_valid, y_pred))
print(tmp_rmse)
models_xgb.append(model_xgb)
rmses_xgb.append(tmp_rmse)
oof_xgb[val_index] = y_predsum(rmses_xgb)/len(rmses_xgb)
0.3253706897276935평균 RSME 결과는 0.3253706897276935 으로 나왔다.
테스트 데이터셋으로 확인하면
xgb_test=xgb.DMatrix(x_test)
test_rmses_xgb=[]
for model in models_xgb:
pred = model.predict(xgb_test)
tmp_rmse = np.sqrt(mean_squared_error(y_test, pred))
test_rmses_xgb.append(tmp_rmse)
sum(test_rmses_xgb)/len(test_rmses_xgb)0.18786965799697064평균 RMSESMS 0.18786965799697064 로 좋은 결과가 나왔다.
이렇게 정확도를 올린 상태로 각 변수마다 중요도를 다시 확인해보았다.
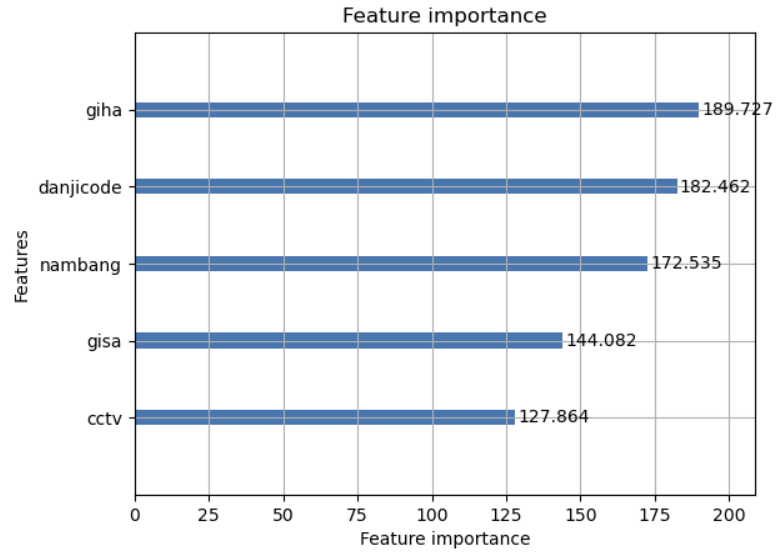
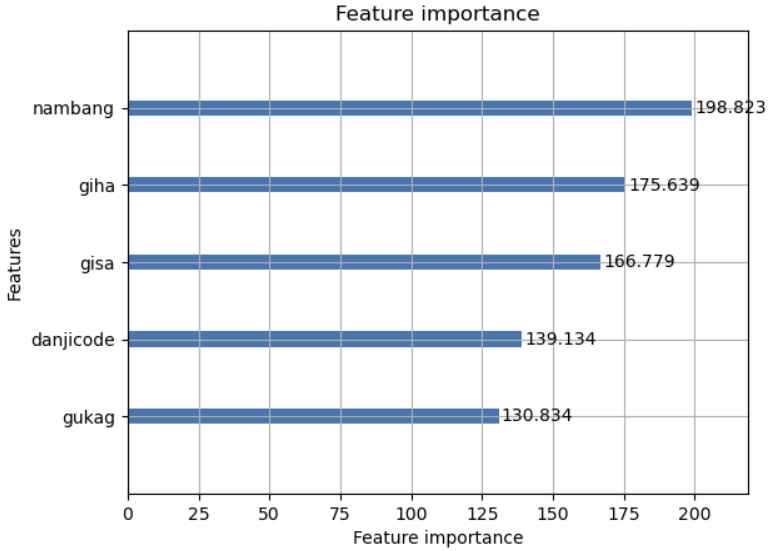
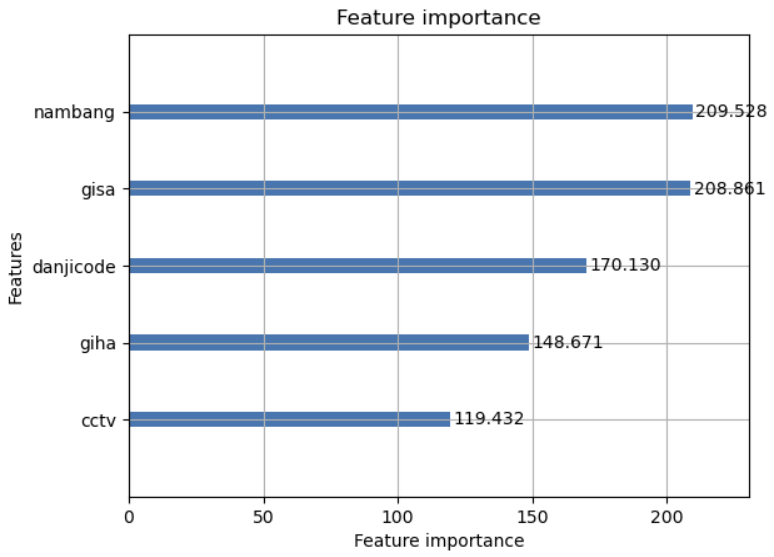
2. 아파트의 외적요소와 아파트 값의 관계
다음은 아파트단지의 외적요소의 영향을 살펴보도록 하겠다.
대형마트, 학교, 지하철역, 은행 등과 아파트 단지주변에 몇개가 있는지 데이터를 수집하였다.
위에 같은 방식으로 똑같이 분석을 진행하였다.
LightGBM : 0.2770847613524276
XGBoost : 0.2824977158149639
의 결과로 아파트 단지의 내적요소로 분석했을 때보다 더 정확도가 높은 것으로 확인되었다.
따라서 아파트 단지의 값을 예측하는데 있어, 내적요소보다는 외적요소가 더 중요한 변수값이라고 판단된다.
중요도가 높은 변수들을 살펴보겠다.
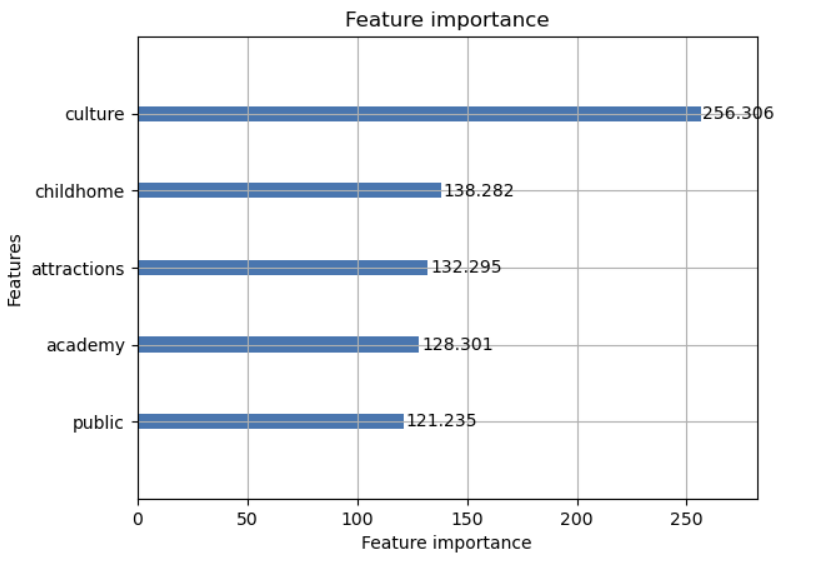
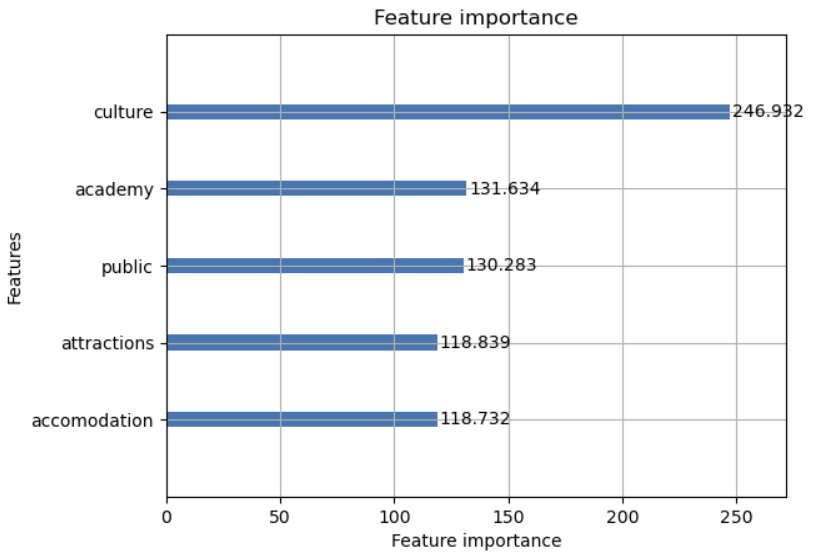
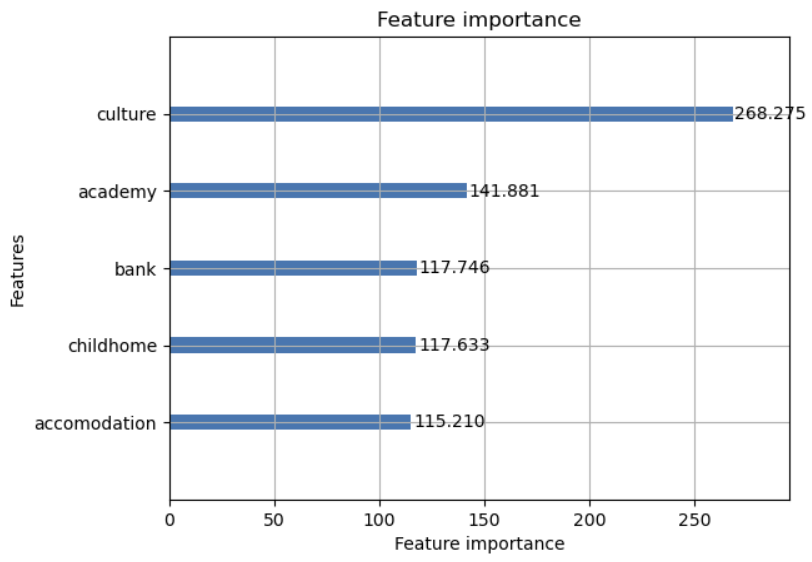
문화시설, 학원, 은행, 어린이집, 관광명소, 공공기관이 중요도 높은 변수로 설정되었다.
그 중에서도 문화시설이 압도적으로 높은 중요도를 보여주었다.
흔히 알고있는 역세권 아파트가 비싸다고 알려져 있었지만
주변에 지하철역이 가까이 있다고해서 아파트값에 큰 영향을 주지 못한다고 볼 수 있다.
아니면 무엇인가 고려하지 못한 부분이 있다고 판단된다.
3 . 아파트의 내적&외적요소 모두 고려
위와 같은 방식으로 내적요소와 외적요소를 모두 통합하여 분석을 진행하였다.
LightGBM : 0.23049679492599892
XGBoost : 0.24302660931748507
으로 데이터와 양과 카테고리가 많이 생길 수록 예측을 하는데 있어, 정확도를 올릴 수 있는 것 같다.
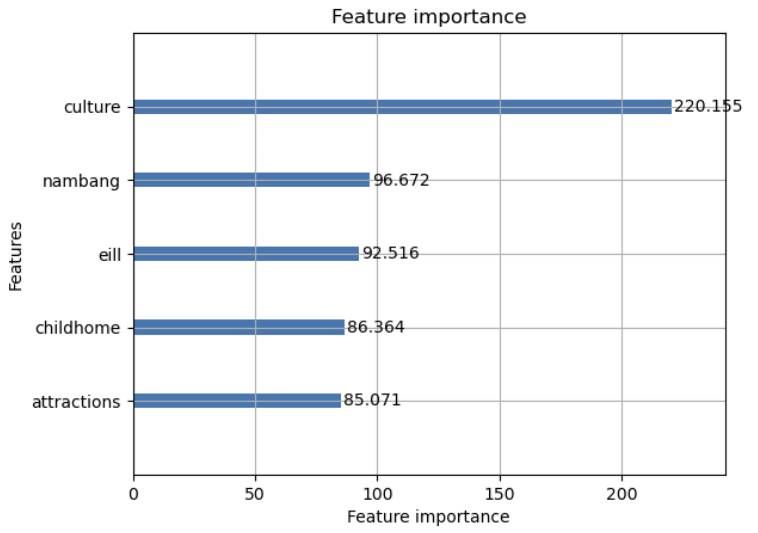
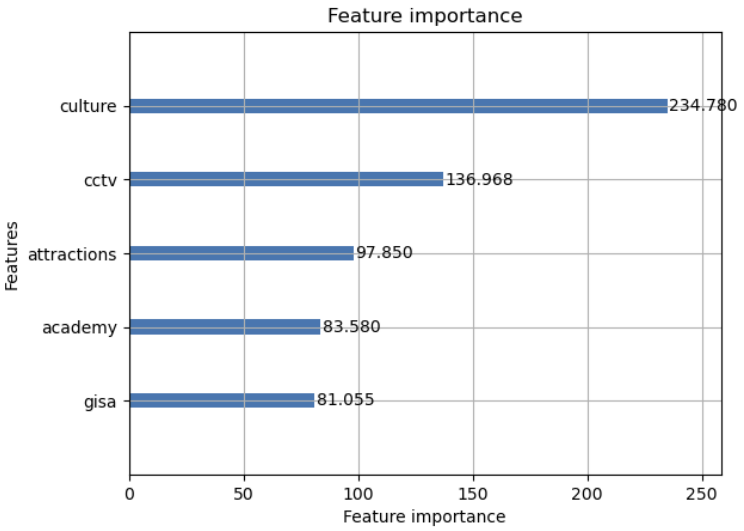
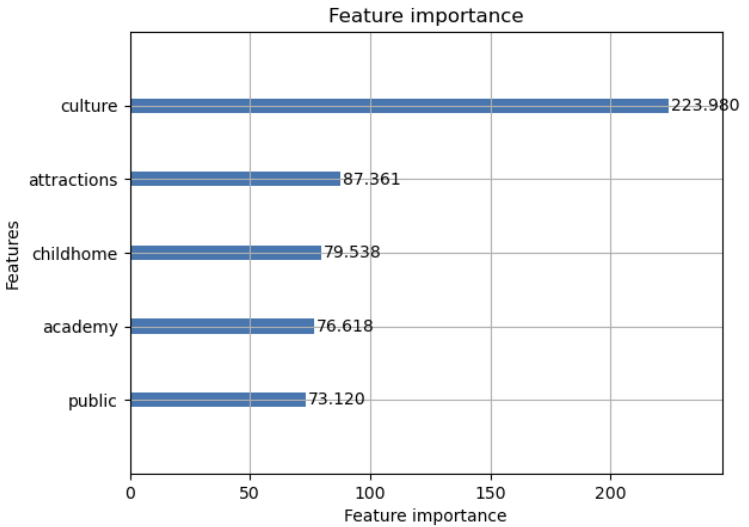
전체 데이터셋으로 분석한 결과 문화시설, 난방방식, CCTV개수, 학원, 관광명소, 어린이집, 유치원의 개수가 중요한 요소로 선전되었다.
아파트 단지 주변과 안에 해당하는 요소, 시설이 갖춰진다면 아파트 값이 상승할 수 있다고 판단되어 진다.
그럼 이렇게 찾은 아파트 값에 있어서 중요한 요소들을 갖추고 있거나 개수가 많을 수록 아파트 값은 증가함수를 보이는지 생각해봤다.
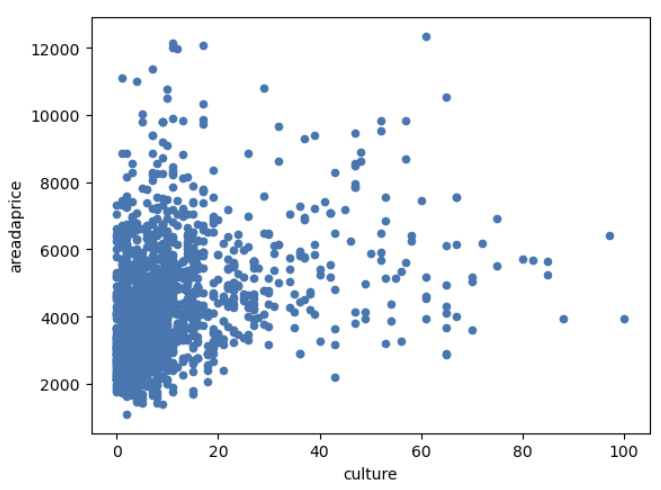
가장 중요한 요소라고 분석되었던 '문화시설의 개수'이다. 무조건적으로 주변에 문화시설의 개수가 많다고해서
아파트가격이 높다고 판단할 순 없지만 30개에서 60개 사이의 데이터 경향을 살펴보니 개수에 따라 가격이 상향하는 모습을 조금이라도 확인은 할 수 있었다.
그래서 카테고리별로 가장 이상적인 시설의 개수를 선정할 필요성을 느꼈다.
그래서 가격이 높을 수 있는 가장 적절한 개수를 세팅하고
그 이상적인 설정안에 들어있는 아파트임에 불구하고 가격이 다른 아파트보다 현저하게 떨어지는 아파트를 선별하고
그 아파트가 현재 저평가되어있다고 판단하려고 하였다.
4. 저평가된 아파트 선정하기(z-score)
import pymysql
import pandas as pd
import numpy as np
from sqlalchemy import create_engine
pymysql.install_as_MySQLdb()
class mysqlDB:
def __init__(self):
self.conn = pymysql.connect(
user='root',
passwd='*******',
host='localhost',
db='test',
charset='utf8')
self.cursor = self.conn.cursor()
print("connection")
def DBcontact(self, sql):
self.cursor.execute(sql)
self.rows = self.cursor.fetchall()
data = pd.read_sql_query(sql, self.conn)
return data
def InsertDataFrame(self, data, table_name):
engine = create_engine("mysql+pymysql://{user}:{pw}@localhost/{db}"
.format(user="root",
pw="*******",
db="test"))
self.co = engine.connect()
data.to_sql(name="zscoredata_market", con=engine,
if_exists='append', index=False)
self.co.close()
def makeguColumn(self):
sql = """SELECT doro
FROM dataset1;
"""
data = self.DBcontact(sql)
data = data['doro'].str.split(" ", 2, expand=True)[1]
data = pd.DataFrame(data)
data.columns = ["gu"]
data_gu = data.drop_duplicates(['gu'])
# self.InsertDataFrame(data_gu)
return data_gu
def makeZ_score_market(self):
data = self.makeguColumn()
for j in range(len(data)):
for i in range(0, 5):
try:
sql = """SELECT nambang,culture,attractions,childhome, academy,cctv,gisa, giha, school, areadaprice
FROM dataset1
WHERE doro like "%{0}%" AND market = {1};
"""
sql = sql.format(data['gu'].iloc[j], i)
# print(sql)
self.DBcontact(sql)
df = pd.DataFrame(self.rows, columns=[
'nambang','culture','attractions','childhome', 'academy','cctv','gisa', 'giha', 'school', 'areadaprice'])
df_data = df['areadaprice']
mean = np.mean(df_data)
std = np.std(df_data)
if len(df_data) == 0: continue
z_score = [(y-mean)/std for y in df_data]
z_score = [x for x in z_score if x<-1.0]
if len(z_score) == 0: continue
df_z = pd.DataFrame(z_score)
df_z.columns = ['zscore_market']
df = pd.concat([df, df_z], join = 'inner', axis=1)
engine = create_engine("mysql+pymysql://{user}:{pw}@localhost/{db}"
.format(user="root",
pw="******",
db="test"))
self.co = engine.connect()
df.to_sql(name="zdata_market", con=engine, if_exists='append', index=False)
self.co.close()
except ZeroDivisionError:
continue
def makeZ_score_hospital(self):
data = self.makeguColumn()
for j in range(len(data)):
for i in range(10, 31):
try:
sql = """SELECT nambang,culture,attractions,childhome, academy,cctv,gisa, giha, school, areadaprice
FROM dataset1
WHERE doro like "%{0}%" AND hospital = {1};
"""
sql = sql.format(data['gu'].iloc[j], i)
# print(sql)
self.DBcontact(sql)
df = pd.DataFrame(self.rows, columns=[
'nambang','culture','attractions','childhome', 'academy','cctv','gisa', 'giha', 'school', 'areadaprice'])
df_data = df['areadaprice']
mean = np.mean(df_data)
std = np.std(df_data)
if len(df_data) == 0: continue
z_score = [(y-mean)/std for y in df_data]
z_score = [x for x in z_score if x<-1.0]
if len(z_score) == 0: continue
df_z = pd.DataFrame(z_score)
df_z.columns = ['zscore_hospital']
df = pd.concat([df, df_z], join = 'inner', axis=1)
engine = create_engine("mysql+pymysql://{user}:{pw}@localhost/{db}"
.format(user="root",
pw="*******",
db="test"))
self.co = engine.connect()
df.to_sql(name="zdata_hospital", con=engine, if_exists='append', index=False)
self.co.close()
except ZeroDivisionError:
continue
def makeZ_score_amenitiesCnt(self):
data = self.makeguColumn()
for j in range(len(data)):
for i in range(0, 5):
try:
sql = """SELECT nambang,culture,attractions,childhome, academy,cctv,gisa, giha, school, areadaprice
FROM dataset1
WHERE doro like "%{0}%" AND amenitiesCnt = {1};
"""
sql = sql.format(data['gu'].iloc[j], i)
# print(sql)
self.DBcontact(sql)
df = pd.DataFrame(self.rows, columns=[
'nambang','culture','attractions','childhome', 'academy','cctv','gisa', 'giha', 'school', 'areadaprice'])
df_data = df['areadaprice']
mean = np.mean(df_data)
std = np.std(df_data)
if len(df_data) == 0: continue
z_score = [(y-mean)/std for y in df_data]
z_score = [x for x in z_score if x<-1.0]
if len(z_score) == 0: continue
df_z = pd.DataFrame(z_score)
print(df_z)
df_z.columns = ['zscore_amen']
df = pd.concat([df, df_z], join = 'inner', axis=1)
engine = create_engine("mysql+pymysql://{user}:{pw}@localhost/{db}"
.format(user="root",
pw="*******",
db="test"))
self.co = engine.connect()
df.to_sql(name="zdata_amen", con=engine, if_exists='append', index=False)
self.co.close()
except ZeroDivisionError:
continue
def getUnderhouse(self):
sql = """SELECT doro
FROM zdata_amen, zdata_hospital, zdata_market;
"""
self.cursor.execute(sql)
self.rows = self.cursor.fetchall()
# columns=['nambang','culture','attractions','childhome', 'academy','cctv','gisa', 'giha', 'school', 'areadaprice']
df = pd.DataFrame(self.rows, columns=[
'nambang','culture','attractions','childhome', 'academy','cctv','gisa', 'giha', 'school', 'areadaprice'])
print(df)
data = df['areadaprice']
mean = np.mean(data)
std = np.std(data)
z_score = [(y-mean)/std for y in data]
df_z = pd.DataFrame(z_score)
df_z.columns = ['z_score']
df_all = pd.concat([df, df_z], axis=1)
return df_all
# def insertHouseInfo(self):
if __name__ == '__main__':
a = mysqlDB()
a.makeZ_score_amenitiesCnt()
a.makeZ_score_hospital()
a.makeZ_score_market()저평가된 아파트를 선별하기 위해서 위에서 설명했던대로 z-score값을 구해 평균보다 밑으로 동 떨어져 있는 데이터를 찾아보려고 했다.
데이터의 양이 많아 MYSQL 데이터베이스 프로그램을 사용하여 데이터를 옮기고 계산해주었다.

각 카테고리별로 가장 이상적인 개수를 선정하고 데이터를 모으고 z-score값을 계산해주었다.
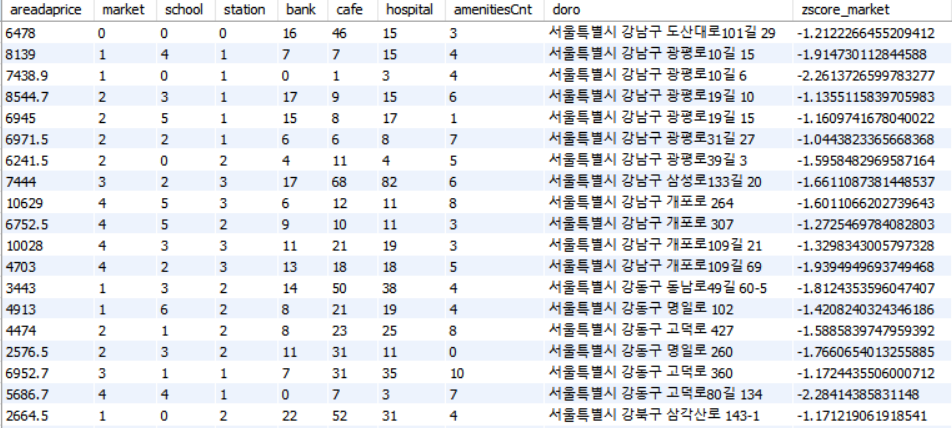
위 사진이 MYSQL의 화면을 캡쳐한 이미지이다. 가장 우측에 보이는 값이 Z-score값이고 동떨어져있는 값의 기준으로 -2보다 밑으로 정하였다.
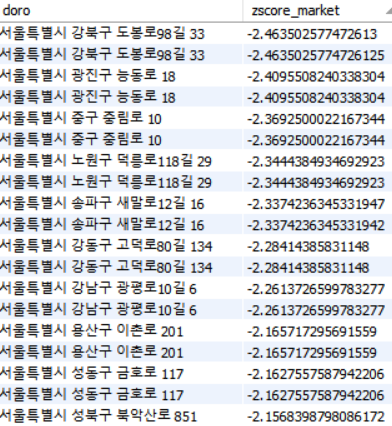
그리고나서 z-score값을 기준으로 정렬을 해주고 저평가된 아파트 데이터 셋을 만들어봤다.
위에 아파트를 구매한다면 이상적인 조건을 다 만족하고 있는 아파트이기 때문에
향후 그 아파트값이 상승할 확률이 높다고 판단할 수 있다.
Ⅴ. Related Work
https://nurilee.com/2020/04/03/lightgbm-definition-parameter-tuning/
LightGBM 이란? 그리고 Parameter 튜닝하기
LightGBM에 관한 좋은 medium 포스트가 있어서 한글로 번역한 내용을 공유드려봅니다 :) Pushkar Mandot의 원문 바로가기: 안녕하세요, 머신러닝은 이 세상에서 가장 빠르게 성장하는 분야입니다. 매일
nurilee.com
https://for-my-wealthy-life.tistory.com/24
https://kicarussays.tistory.com/38https://riverzayden.tistory.com/17https://dining-developer.tistory.com/7
예측력이 좋은 XGBoost Regression 개념 및 python 예제
XGBoost Regression 방법의 모델은 예측력이 좋아서 주로 많이 사용된다. 1. 정의 약한 분류기를 세트로 묶어서 정확도를 예측하는 기법이다. 욕심쟁이(Greedy Algorithm)을 사용하여 분류기를 발견하고 분
riverzayden.tistory.com
[논문리뷰/설명] LightGBM: A Highly efficient Gradient Boosting Decision Tree
LightGBM은 예전에 한 프로젝트에서 정형 데이터 (Table 형태의 데이터) 에 여러 머신러닝 기법들을 적용해보던 중에 발견한 방법이었습니다. CPU만 사용하면서도 GPU를 쓰는 XGBoost보다 훨씬 더 빠르
kicarussays.tistory.com
Ⅵ. Conclusion: Discussion
이번 과제를 통해 머신러닝 기법 중 하나인 LightGBM과 XGBOOST 모델을 제대로 사용해본 경험이 되어 좋은 시간이었던 거 같다. 아파트의 값을 예측하는 것을 초점으로 맞추었다보니 가격을 맞추는데 있어 중요한 요소가 무엇인지는 제대로 알 수 있었지만 그 값이 어떻게 형성되어야 아파트 가격이 높은 변수의 값을 만족할 수 있는지 파악하기엔 능력도 부족하고 좋은 생각이 떠오르지 못했던 거 같다.
그래서 생각해낸 방법이 Z-SCORE값을 구해서 현재의 아파트 가격이 평균보다 많이 떨어져있지만 주변환경요소가 좋아 언제든지 가격이 상승할 수 있을 거라고 판단하였는데
이 방법이 옳은 방법이라고 하기에는 확신이 없다.
예측을 하고나서 그 변수들 하나하나를 만져보면서 원하는 결과를 만들어내야 하는 시간과 능력이 필요하다는 것을
이번 프로젝트를 진행하면서 알게된 거 같다.
<프로젝트 설명 동영상>
부끄러워서 삭제