오늘은 원하는 키워드를 구글 뉴스에서 크롤링하는 파이썬 코드를 작성해보려고 합니다.
https://news.google.com/home?hl=ko&gl=KR&ceid=KR:ko
https://news.google.com/home?ceid=KR%3Ako&gl=KR&hl=ko
news.google.com
url을 자세히 살펴보겠습니다.
구글 뉴스에서 특정 키워드를 검색하면 url이 어떤 형태로 변경되는지 살펴보겠습니다.

https://news.google.com/search?q=네이버&hl=ko&gl=KR&ceid=KR%3Ako
검색창에서 "네이버" 라고 검색했는데 url에 변화가 생겼습니다. q=네이버 이라는 텍스트가 추가되었는데 여기서 q는 query의 약자입니다.
원하는 검색어를 url에 q={키워드}의 형태로 request요청하면 될 것으로 보입니다.
import requests
from bs4 import BeautifulSoup
import re
from datetime import datetime, timedelta
def google_news_crawler(query):
# Google News 검색 URL
url = f"https://news.google.com/search?q={query}&hl=ko&gl=KR&ceid=KR%3Ako"
# HTTP GET 요청 보내기
response = requests.get(url)
# HTTP 요청이 성공하면 HTML 파싱
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
print(soup)
else:
print("HTTP 요청 실패")
if __name__ == "__main__":
query = "네이버"
google_news_crawler(query)키워드는 네이버로 검색하여 우선 html.parser 결과를 가져와보겠습니다.

전체 html 코드가 출력이 잘 되는 것을 확인할 수 있습니다.
여기서 우리는 html 태그를 통해 필요한 정보만 추출해보도록 하겠습니다.
추가로 가장 최근 데이터를 가져오기 위해 시간 필터를 적용해보겠습니다. 최근 1시간동안 올라온 데이터를 검색하기 위해선

이렇게 필터를 열고 날짜를 지난 1시간 을 선택하고 검색합니다. 또한 정확도를 올리기 위하여 포함된 단어가 아닌 정확한 문구 필터를 사용하여 검색을 진행해보겠습니다.
필터를 적용하면 검색창에 "네이버"when:1h 으로 변경됩니다. 이 검색어로 sql 요청을 하면 원하는 데이터를 가져올 수 있나봅니다.

필터를 적용하면 url의 형태 또한 변경됩니다.

q="네이버"when:h1으로 변경됩니다.
검색 결과는 다음과 같습니다.

뉴스 카드를 살펴보면 언론사, 뉴스 제목, 시간, 뉴스 링크 데이터가 보여지고 있는 걸 알 수 있습니다.
이 4가지의 데이터를 추출해보겠습니다.
F12를 눌러 개발자도구를 열어봅니다.
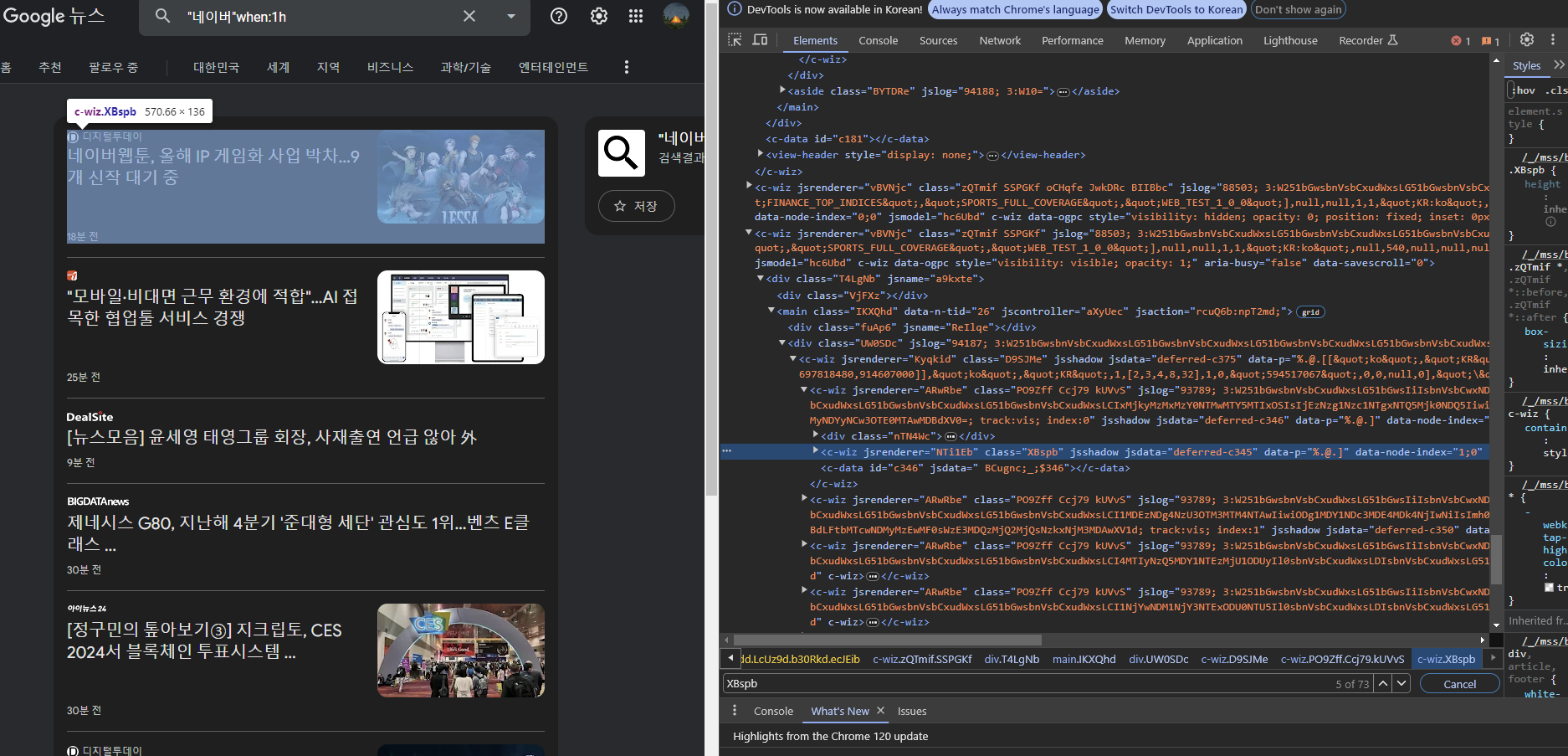
어떤 태그안에 데이터가 들어가 있는지 확인할 수 있습니다.
뉴스카드는 c-wiz 태그 class는 XBspb 에 속해 있다는 것을 알 수 있습니다.
이런 방식으로 데이터를 모두 추출해보겠습니다.
코드를 살펴보면 모든 뉴스카드를 가져오기 위해서 select를 사용하였습니다.
allNews = soup.select('c-wiz.XBspb')모든 뉴스를 가져오고 for문을 통해 뉴스 하나씩 돌아가면서 데이터를 추출하는 방식으로 코드를 작성하였습니다.
for news in allNews:
# 언론사 추출
press = news.select_one('div.vr1PYe').text
# 제목 추출
title = news.select_one('a.JtKRv').text
# 날짜 추출
datetime_str = news.select_one('div.UOVeFe time.hvbAAd')['datetime']
# datetime 값을 파싱
dt = datetime.strptime(datetime_str, '%Y-%m-%dT%H:%M:%SZ')
# 9시간을 더하여 한국 시간으로 변환
korean_time = dt + timedelta(hours=9)
# 분까지만 출력 (strftime을 사용하여 포맷팅)
formatted_time = korean_time.strftime('%Y-%m-%d %H:%M')
# 링크 추출
link = news.select_one('a.JtKRv')['href']
link = link.lstrip('.')
print(press)
print(title)
print(formatted_time)
print("https://news.google.com"+link)
print("")날짜 추출 부분이 살짝 까다로웠는데, 지난 1시간이내의 뉴스들이라 text상으로는 13분전, 23분전과 같은 데이터가 들어가 있었습니다.
하지만 정말 필요한건 정확한 뉴스 게시 날짜와 시간이기 때문에 다른 방법을 찾아봐야 했습니다.
html 코드를 살펴보면
<time class="hvbAAd" datetime="2024-01-03T23:12:00Z">18분 전</time>이런 형태로 들어가 있습니다. 여기서 datetime 값을 추출해서 날짜와 시간을 정확히 추출하고자 하였습니다.
구글이라 한국시간이 아닌 미국시간? 이라 9시간을 더 해줘서 정확한 한국시간을 계산하여 출력하였습니다.
여기까지 구글 뉴스 크롤링 이었습니다.
감사합니다.
전체 코드
import requests
from bs4 import BeautifulSoup
import re
from datetime import datetime, timedelta
def google_news_crawler(query):
# Google News 검색 URL
url = f"https://news.google.com/search?q=\"{query}\"when%3A1h&hl=ko&gl=KR&ceid=KR%3Ako"
# HTTP GET 요청 보내기
response = requests.get(url)
# HTTP 요청이 성공하면 HTML 파싱
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 뉴스 제목과 링크 가져오기
allNews = soup.select('c-wiz.XBspb')
for news in allNews:
# 언론사 추출
press = news.select_one('div.vr1PYe').text
# 제목 추출
title = news.select_one('a.JtKRv').text
# 날짜 추출
datetime_str = news.select_one('div.UOVeFe time.hvbAAd')['datetime']
# datetime 값을 파싱
dt = datetime.strptime(datetime_str, '%Y-%m-%dT%H:%M:%SZ')
# 9시간을 더하여 한국 시간으로 변환
korean_time = dt + timedelta(hours=9)
# 분까지만 출력 (strftime을 사용하여 포맷팅)
formatted_time = korean_time.strftime('%Y-%m-%d %H:%M')
# 링크 추출
link = news.select_one('a.JtKRv')['href']
link = link.lstrip('.')
print(press)
print(title)
print(formatted_time)
print("https://news.google.com"+link)
print("")
else:
print("HTTP 요청 실패")
if __name__ == "__main__":
query = "네이버"
google_news_crawler(query)
'개발 > Python' 카테고리의 다른 글
| [자료구조] A* 알고리즘 (1) | 2024.01.30 |
|---|---|
| [python] Lambda 함수: 간결한 함수 정의와 활용 (1) | 2024.01.21 |
| [Python] 윈도우 venv 가상환경 설치하기 (1) | 2023.01.25 |
| [Python] venv 가상환경 설정이 필요한 이유는? (0) | 2023.01.25 |



